
WebUI LORA 생성용 kohya_ss 설치방법
WebUI에서 kohya_ss 를 사용하면 Dreambooth 기반으로 LORA를 생성할 수 있도록 UI를 제공해 주는데 이번 글에서는 kohya_ss 설치방법에 대해 알아본다 먼저 윈도우 버튼을 누르고 powershell로 검색을 해 주면
flatsun.tistory.com
위 링크를 통해 kohya_ss 를 설치해 보았다면
이제 LORA를 만들어 볼 수 있게 되었는데
LORA를 간략히 설명해보자면 특정 캐릭터와
그림체를 찍어내는 용도로 사용할 수 있으나
많은 경우에 특정 캐릭터를 찍어내는 용도로
사용한다고 보면 된다
먼저 LORA를 생성하기 전에
데이터용으로 사용할 이미지를 모아
한 폴더 안에 넣어줘야 하는데
따라하기 전에 주의할 점은
실제 인물을 찍어내는 것 보다는
2D 만화 캐릭터를 찍어내는 것이
훨씬 쉽고 유사도가 높기 때문에
이 쪽을 먼저 진행해보고
실제 인물을 진행할 것을 권장한다
이미지는 고화질이고
많은 숫자를 모을 수록 유리한데
여기서 가능하면 동일한 의상을 입고,
한 명만 나온 사진을 위주로 골라야 한다
마구잡이로 넣다 보면
예상치 못한 사람이 튀어나올 수 있고
얼굴과 의상이 뒤섞여서 특정 인물이 아닌
그림체를 가져오게 될 수 있는데
그럴 목적이 아니라면
고화질, 한 인물만, 추상적이지 않은 묘사 등
멀쩡한 그림등을 모으되
30~150장 선으로 모아주면 되고
많이 모을수록 더 좋은 결과를 얻을 수 있다
다만 여기서는 유사하게 찍어내는지
기능만 확인할 것이기 때문에 10장으로 진행한다

이미지를 모두 모았으면
WebUI를 실행한 뒤
Extensions 탭으로 들어와 Install from URL을 누르고
https://github.com/picobyte/stable-diffusion-webui-wd14-tagger
를 넣어준 뒤 Install 하고 WebUI를 다시 실행해주자

이제 Tagger 메뉴로 들어온 뒤
Batch from directory를 누르고
아까 이미지 넣어둔 경로를 연결한 뒤
하단으로 내려와 네모 표시한
체크박스 3 곳을 체크해주고
Interrogate를 누른 뒤
이미지 넣은 경로로 이동해보면

이미지를 기반으로 태그(프롬프트)를 따둔 것이 보인다
이제부터 kohya_ss를 사용하기 시작할건데
제대로 못 따라하면 오류의 늪에 빠지기 때문에
두 눈 크게 뜨고 정신 똑바로 차리고 진행하자
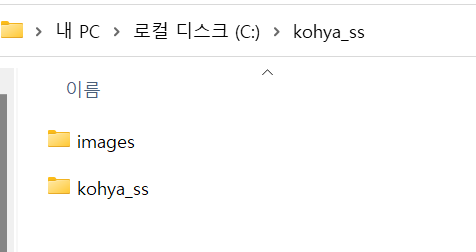
먼저 kohya_ss를 설치한 경로로 이동한 뒤
images 폴더를 생성해준다

안으로 들어와서는 output 폴더만 생성해주면 끝이다
(나머지 3 폴더는 자동 생성됨)
이제 kohya_ss를 실행한 뒤 접속해주면

Dreambooth LORA를 선택 한뒤
Source model 탭으로 들어와서
왼쪽에 보이는 아이콘을 눌러준 뒤
그림들을 어느 그림체로 베껴올건지 checkpoint를 선택해주자
내 경우에는 abyssorangemix3 으로 진행한다
이게 아무거나 막 하면 안되는게
LORA를 생성한 후
내가 선택한 checkpoint가 아닌
다른 checkpoint로 변경하면
이미지에 약간 변화가 생기기 때문에
자주 사용해 주는 걸로 사용해주면 된다
이후 오른쪽 옵션도 이렇게 변경해주자
Model Quick Pick > custom
Save trained model as > same source model

이제 Tools 탭으로 이동한 뒤
Dreambooth/LoRA Folder preparation 을 선택하고
instance prompt 에는 iom, doz, oca 중에
아무거나 하나 넣어준 뒤 Class prompt에는
어느 프롬프트를 입력해야
해당 LORA를 잘 호출할지 선택하는 부분인데
tagging을 진행했기 때문에
1girl, 1boy 등
본인이 인지할 수 있는 값만 써주면 된다
다음으로 Training images는
아까 이미지 모아놓고 태깅 진행한 폴더 지정하고
Repeats 는 100 주고
(적게 줄 수록 다른 그림, 너무 높게 주면 박살남)
마지막으로 Destination training directory에는
아까 kohya_ss/images 이쪽으로 설정해주면 된다
이후 Prepare training data 를 눌러주면
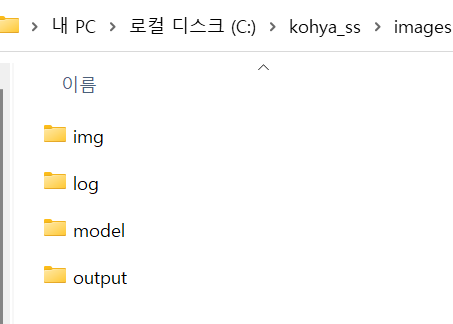

신규 폴더들이 생기고 img 안으로 들어가보면
내가 가져온 샘플 이미지와
태깅 파일이 들어간 것이 보인다

이제 Traning parameters 로 이동해서
옵션을 설정해줄 시간인데
그래픽카드가 지포스 10으로 시작한다면
우측 Optimizer에서 AdamW8 을 사용해주면 되고
속도를 올려주는 부분은
Train batch size, Learning rate 부분이고
본인의 VRAM 크기에 따라
유동적으로 늘렸다 줄였다 해주면 된다
그리고 Max resolution 은 64 단위로 늘려주면
완성본의 품질이 상승하지만
그에 비례해서 만들어지는 시간이 길어진다
LORA의 생성시간은 짧아야 3분
길면 몇시간을 넘어가는 경우가 많기 때문에
테스트 용도라면 기본 옵션인
512, 512를 유지하는 것을 권장한다
나머지 옵션은 이미지와 동일하게 가고
하단에 위치한 Advanced Configuration 을 눌러준 후

Clip skip 부분을 2로 놓아주면 된다
(LORA가 프롬프트 잘 알아먹게 하기 위해서)
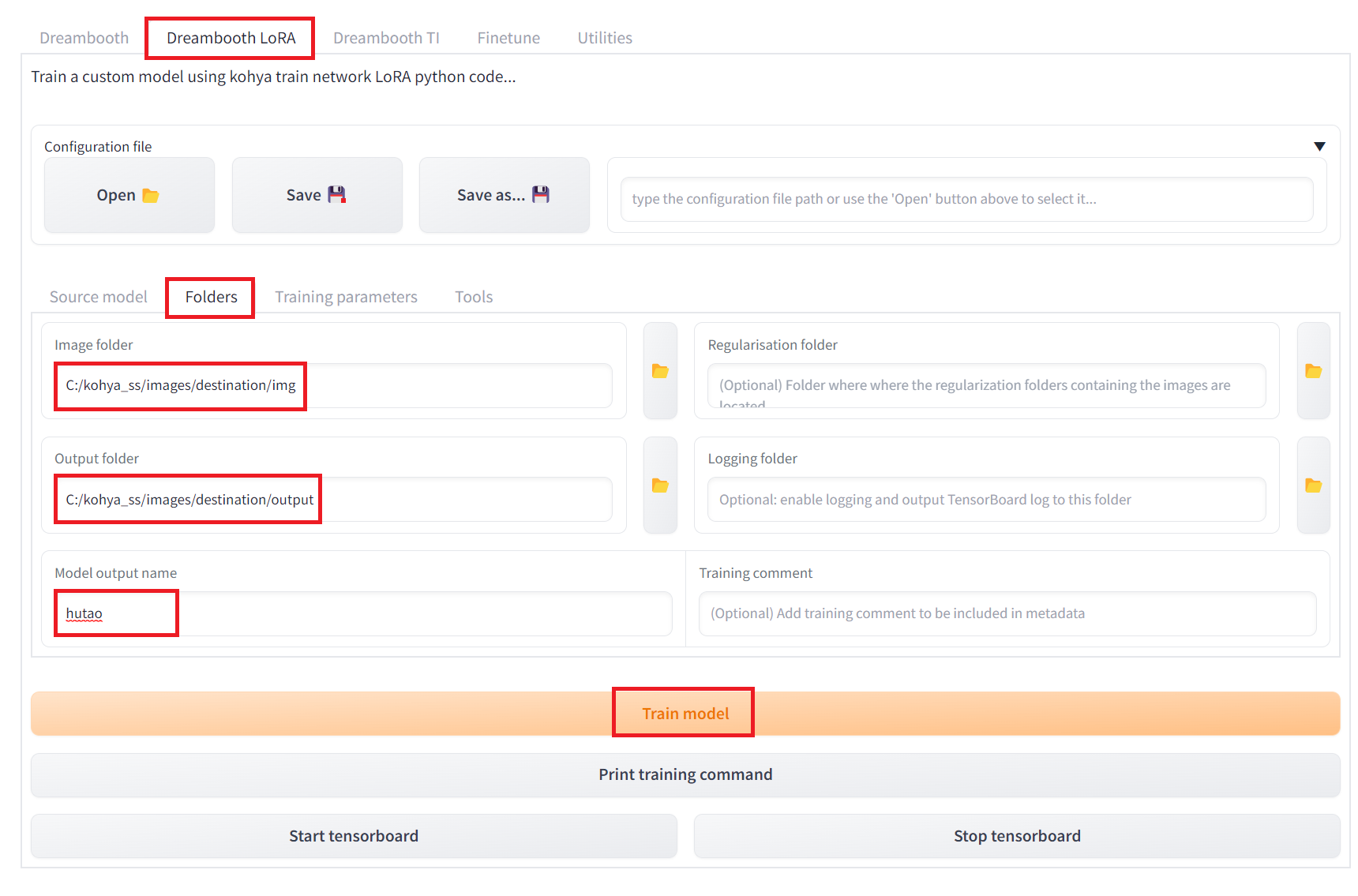
이제 진짜 생성 직전까지 왔다
Folders 탭으로 넘어온 뒤
Image Folder는
아까 Prepare training data 를 눌러 생성된
img 폴더를 지정해주면 되고
(해당 폴더 안의 폴더를 지정해주면 에러남)
ouput은 결과물을 어디에 받을까 하는 내용인데
아까 output 폴더를 만들어 두었으니
거기에 그대로 넣어주면 되고
Model output name은
나중에 WebUI에서
LORA 이름을 뭐라고 지정할지 선택한 후
Train Model을 눌러주자

이제 사진의 갯수와 옵션을
어떻게 설정했느냐에 따라
오랜 시간을 기다리게 되는데
내 경우에는 사진 10장만 사용해서
4분 정도가 걸렸는데
너무나도 쉽게 한시간을 넘어갈 수 있기 때문에
누르기 전에는 신중에 신중을 기해야 한다

이후 모든 작업이 끝나고 나면
output 폴더로 이동해서 - 00~ 이 없는
(00 붙은 파일은 작업 분기별로 끊어 생성된 파일)
모델명 파일을 복사해준 후
C:\stable-diffusion-webui\models\Lora
위 경로에 넣어주자
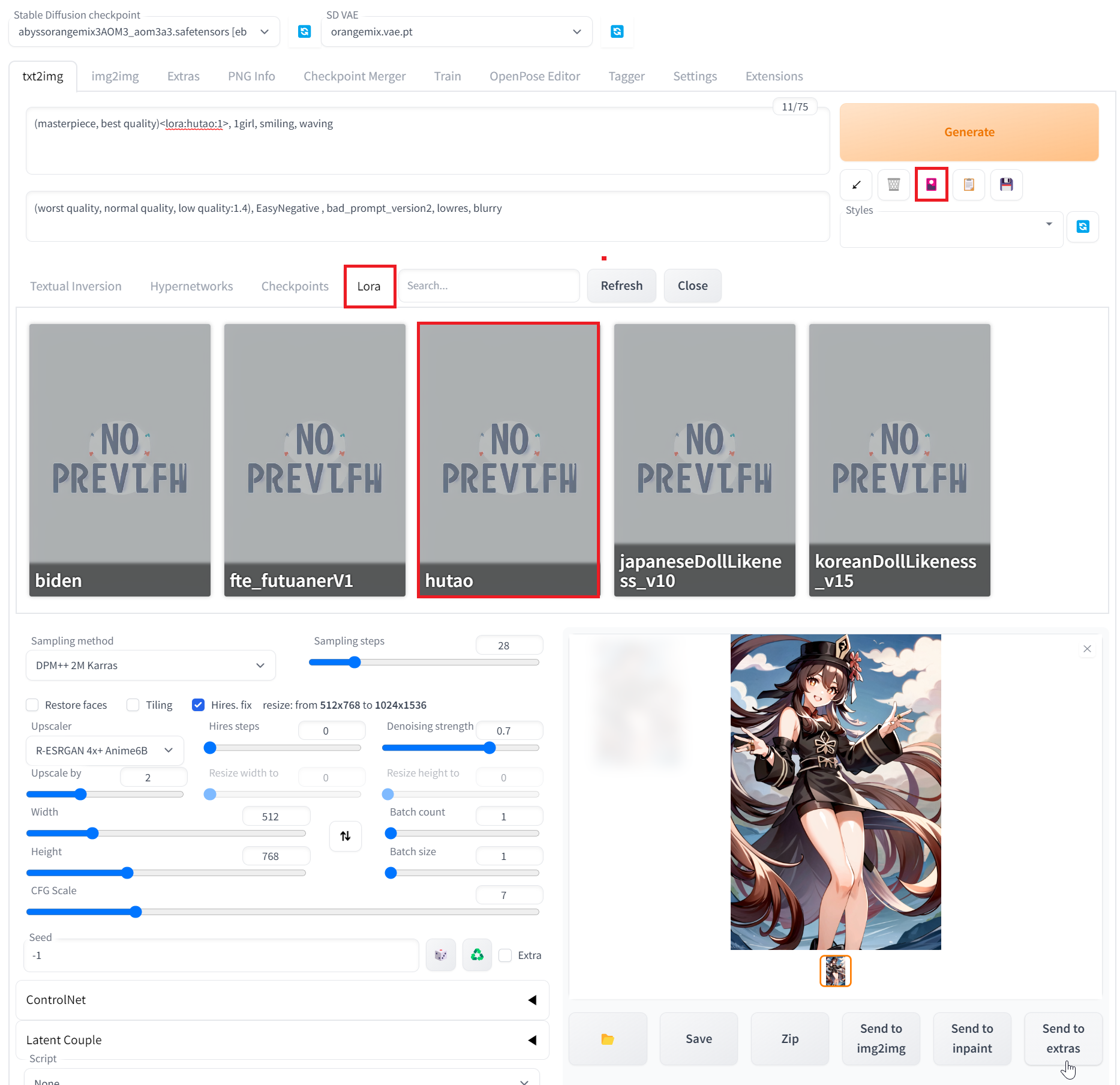
이제 WebUI로 이동해서 우측의 버튼을 누르고
Lora를 선택해서 생성한 LORA를 눌러주거나
혹은 <lora:lora명:1>
이런 식으로 사용해주면 되는데
숫자는 1에 가까울 수록
LORA와 동일하게 나오며
0에 가까울 수록
모델이 뭔지 알기 힘들게 된다
'잡담 > WebUI(stable-diffusion)' 카테고리의 다른 글
| kohya_ss AssertionError: when caching latents 에러 해결방법 (0) | 2023.03.11 |
|---|---|
| kohya_ss No data found. Please verify arguments 에러 해결방법 (0) | 2023.03.11 |
| WebUI LORA 생성용 kohya_ss 설치방법 (11) | 2023.03.10 |
| WebUI --no-half-vae 에러 해결방법 (0) | 2023.03.10 |
| WebUI 엔비디아 30, 40 시리즈 cuDNN 변경으로 속도 올리기 (2) | 2023.03.10 |
댓글